Contrastive Learning of Musical Representations
PyTorch implementation of Contrastive Learning of Musical Representations by Janne Spijkervet and John Ashley Burgoyne.
![]()
![]()
![]()
![]()
You can run a pre-trained CLMR model directly from within your browser using ONNX Runtime: here.
In this work, we introduce SimCLR to the music domain and contribute a large chain of audio data augmentations, to form a simple framework for self-supervised learning of raw waveforms of music: CLMR. We evaluate the performance of the self-supervised learned representations on the task of music classification.
- We achieve competitive results on the MagnaTagATune and Million Song Datasets relative to fully supervised training, despite only using a linear classifier on self-supervised learned representations, i.e., representations that were learned task-agnostically without any labels.
- CLMR enables efficient classification: with only 1% of the labeled data, we achieve similar scores compared to using 100% of the labeled data.
- CLMR is able to generalise to out-of-domain datasets: when training on entirely different music datasets, it is still able to perform competitively compared to fully supervised training on the target dataset.
This is the CLMR v2 implementation, for the original implementation go to the v1 branch
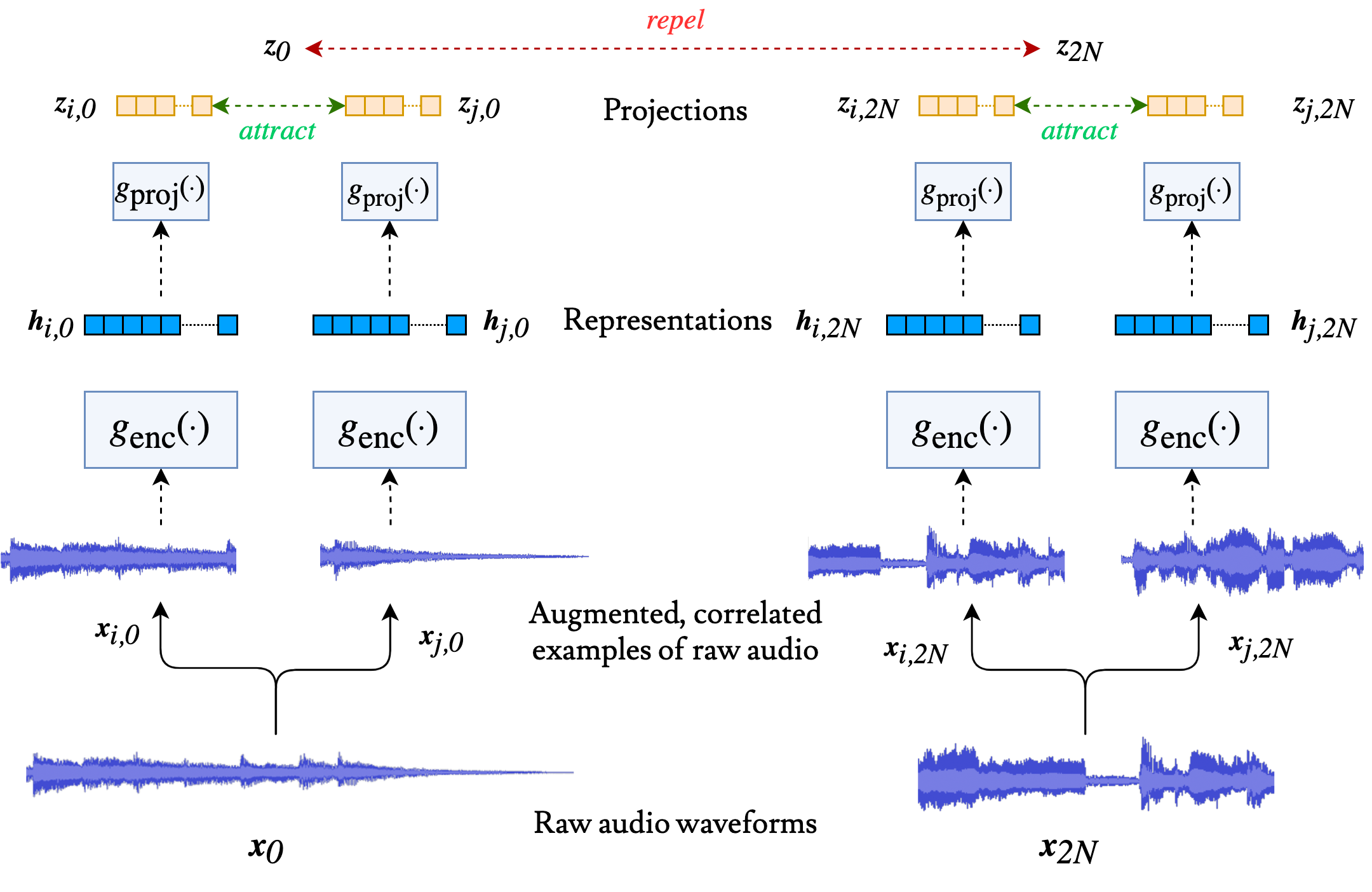
This repository relies on my SimCLR implementation, which can be found here and on my torchaudio-augmentations package, found here.
Quickstart
git clone https://github.com/spijkervet/clmr.git && cd clmr
pip3 install -r requirements.txt
# or
python3 setup.py install
The following command downloads MagnaTagATune, preprocesses it and starts self-supervised pre-training on 1 GPU (with 8 simultaneous CPU workers) and linear evaluation:
python3 preprocess.py --dataset magnatagatune
# add --workers 8 to increase the number of parallel CPU threads to speed up online data augmentations + training.
python3 main.py --dataset magnatagatune --gpus 1 --workers 8
python3 linear_evaluation.py --gpus 1 --workers 8 --checkpoint_path [path to checkpoint.pt, usually in ./runs]
Pre-train on your own folder of audio files
Simply run the following command to pre-train the CLMR model on a folder containing .wav files (or .mp3 files when editing src_ext_audio=".mp3" in clmr/datasets/audio.py). You may need to convert your audio files to the correct sample rate first, before giving it to the encoder (which accepts 22,050Hz per default).
python preprocess.py --dataset audio --dataset_dir ./directory_containing_audio_files
python main.py --dataset audio --dataset_dir ./directory_containing_audio_files
Results
MagnaTagATune
| Encoder / Model | Batch-size / epochs | Fine-tune head | ROC-AUC | PR-AUC |
|---|---|---|---|---|
| SampleCNN / CLMR | 48 / 10000 | Linear Classifier | 88.7 | 35.6 |
| SampleCNN / CLMR | 48 / 10000 | MLP (1 extra hidden layer) | 89.3 | 36.0 |
| SampleCNN (fully supervised) | 48 / - | - | 88.6 | 34.4 |
| Pons et al. (fully supervised) | 48 / - | - | 89.1 | 34.92 |
Million Song Dataset
| Encoder / Model | Batch-size / epochs | Fine-tune head | ROC-AUC | PR-AUC |
|---|---|---|---|---|
| SampleCNN / CLMR | 48 / 1000 | Linear Classifier | 85.7 | 25.0 |
| SampleCNN (fully supervised) | 48 / - | - | 88.4 | - |
| Pons et al. (fully supervised) | 48 / - | - | 87.4 | 28.5 |
Pre-trained models
Links go to download
| Encoder (batch-size, epochs) | Fine-tune head | Pre-train dataset | ROC-AUC | PR-AUC |
|---|---|---|---|---|
| SampleCNN (96, 10000) | Linear Classifier | MagnaTagATune | 88.7 (89.3) | 35.6 (36.0) |
| SampleCNN (48, 1550) | Linear Classifier | MagnaTagATune | 87.71 (88.47) | 34.27 (34.96) |
Training
1. Pre-training
Simply run the following command to pre-train the CLMR model on the MagnaTagATune dataset.
python main.py --dataset magnatagatune
2. Linear evaluation
To test a trained model, make sure to set the checkpoint_path variable in the config/config.yaml, or specify it as an argument:
python linear_evaluation.py --checkpoint_path ./clmr_checkpoint_10000.pt
Configuration
The configuration of training can be found in: config/config.yaml. I personally prefer to use files instead of long strings of arguments when configuring a run. Every entry in the config file can be overrided with the corresponding flag (e.g. --max_epochs 500 if you would like to train with 500 epochs).
Logging and TensorBoard
To view results in TensorBoard, run:
tensorboard --logdir ./runs